
redis有序集合底层实现
作者:向前的步伐 / 发表: 2022年2月26日 21:00 / 更新: 2022年2月26日 22:37 / redis / 阅读量:675
一、简介
redis完全基于内存操作,所以它的性能出色,而且redis有很丰富的数据类型,在电商项目中后端开发的常用redis解决性能问题。其中有序集合zset就是常用的基本数据类型之一,每个member都带有score,可用于排序相关的功能,比如:价格排序,销售额排序等等。
二、有序集合zset数据结构
有序集合对象的编码可以是ziplist或者skiplist。同时满足以下条件时使用ziplist编码:
- 有序集合对象保存的所有元素的长度都小于 64 字节;
- 有序集合对象保存的元素个数小于128个;
以上两个条件的上限值可通过zset-max-ziplist-value和zset-max-ziplist-entries来修改。
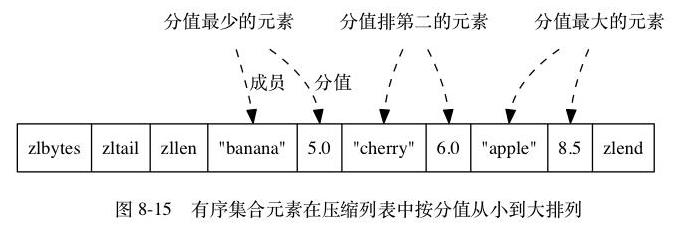
ziplist编码的有序集合使用紧挨在一起的压缩列表节点来保存,第一个节点保存member,第二个保存score。ziplist内的集合元素按score从小到大排序,score较小的排在表头位置。
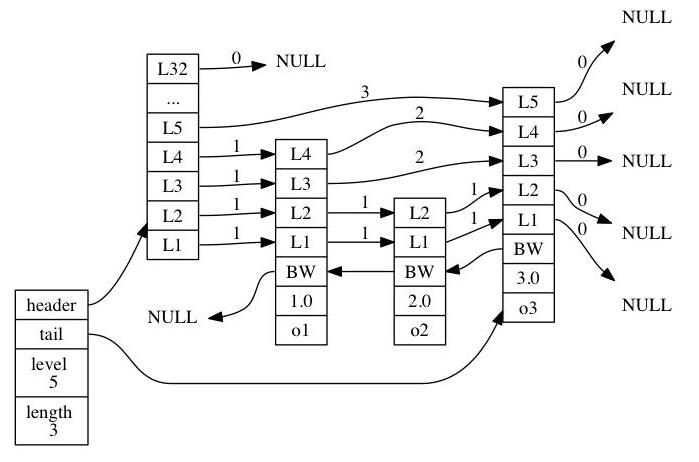
skiplist编码的有序集合底层是一个命名为zset的结构体,而一个zset结构同时包含一个字典和一个跳跃表。跳跃表按score从小到大保存所有集合元素。而字典则保存着从member到score的映射,这样就可以用O(1)的复杂度来查找member对应的score值。虽然同时使用两种结构,但它们会通过指针来共享相同元素的member和score,因此不会浪费额外的内存。
typedef struct zset {
zskiplist *zs1
dict *dict
}
三、理解跳表
跳表其实就是链表的一个演化。在一个链表中,如果我们想要查找某个数据,那么需要从头到尾的遍历查找,直到找到要查询的数据。也就是说,时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。

如果我们每隔一个节点多增加指针指向后面的节点。当我们想查找数据的时候,可以先沿着高层的链表进行查找。当节点的数值比查找数据大时,再往下一层链表中进行查找。比如,我们想查找15,如果数据存在则找到,不存在则直接找到最下层的指针。
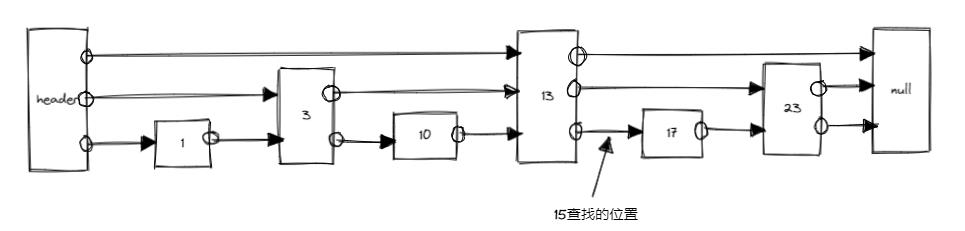
查找的过程:
- 15和最高层的13比较,15比13大,往后走,然后是遇到null,则往下走一层
- 15再和23比较,15比23小,则往下走一层
- 15和17比较,15比17小,再往下走一层
- 没有下一层,则15不存在跳表中,如果此时需要插入数据,则是在图中表示的指针后插入数据
在这个查找过程中,由于新增加的指针,时间复杂度不再是O(N)了,也即我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。
在这个多层的链表结构上,我们去查找15,那么沿着最上层链表首先要比较的是13,发现15比13大,我门只需要往13后面走,一下跳过了13前面所有数字。如此可想,当链表足够长,利用这种多层的链表结构,可以跳过多个下层数据,可以快速找到节点。
skiplist就是这种多层链表的设计。实际上,按照上面的生成链表的方式,一般上层是下层链表节点数 的一半,这样查找过程就类似一个二分查找,使得查找的时间复杂度可以降低到O(log n)。但是,这种结构,很难保证插入数据后,一直保持1:2的对应关系。如果硬要维持1:2,那每次插入数据都要进行调整,带来维护成本增加,这会让时间复杂度重新蜕化成O(n)。删除数据也有同样的问题。
skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)。
#define ZSKIPLIST_MAXLEVEL 32
#define ZSKIPLIST_P 0.25
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
skiplist的插入过程,没插入一个节点,都会获得一个随机层数(level),并且插入的节点,不会影响其他节点的层数。所以,插入的操作只需要修改插入节点前后的指针,不需要对过多的节点进行调整。这就降低了插入操作的复杂度。实际上,这是skiplist的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。
skiplist就是多层指针的一个链表,除了最底层链表拥有所有数据外,越高层数据越稀疏,这些稀疏的链表跳过了一些节点,而且越高层跳过的越多。这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置。在这个过程中,我们跳过了一些节点,从而也就加快了查找速度。
四、为什么采用跳跃表,而不使用平衡树
- 在做范围查找的时候,skiplist比平衡树操作要简单。在平衡树上,我们找到最小值之后,还要以中序遍历的方式找到所有范围内的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
- 平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
