
mysql数据库分库分表
作者:向前的步伐 / 发表: 2020年2月17日 23:27 / 更新: 2020年2月18日 08:37 / mysql / 阅读量:790
一、简介
随着互联网的发展,用户量迅速扩大,对系统的要求也越来越高。关系型数据库容易成为系统的瓶颈,单机的存储能力、连接数、处理能力都有限。当单表的数据量达到1000W或者100G以后,数据库的很多操作性能就会严重下降。此时就要考虑对数据库进行切分,减少数据库的压力,缩短查询时间。
1,影响性能的因素:
数据量:
- mysql单库数据量在5000W以内性能还比较好,超过之后性能会随着数据量的增大而变弱。
- mysql单表的数数据量在500W-1000W之间性能还比较好,超过1000W性能也会下降。
磁盘:
- 因为单个服务的磁盘空间有限,如果在大并发的压力下,所有请求都访问一个节点,会对磁盘IO造成很大的影响。
数据库连接:
- 数据库的连接量也有限,如果一个库有多个类型的数据,当大量的用户同时访问时,数据库的连接数很快就成为瓶颈。
2,数据库的演变:
系统在刚开始构建的时候,单机的数据库时足够使用的,但是随着后面的请求数越来越多,对单机的数据库进行读写形成了一定的压力,这时就要先考虑对数据库进行读写分离,使用多个从库负责读取操作,主库负责写,从库同步更新主库中的数据。
但是在用户量起来之后,写入的数据越来越多,单表中的数据量太大,性能开始下降,这时就需要考虑对数据库进行分库分表,减低单库单表的压力,提升性能。
二、分库分表
当我们开始进行分库分表的时候,就先看造成性能下降的原因是表太多/字段太多,还是数据量太大。如果是表太多/字段太多,就采用垂直拆分,迁移表或者减少单表的字段。如果是数据量太大,就采用水平拆分,按一定的规则将大表拆分为多个小表。
1,垂直拆分:
1)垂直分库:
垂直分库是针对整个系统中,对不同的业务进行拆分,比如用户信息分一个库、商品信息分一个库、订单信息分一个库。这样对数据库进行拆分可以减少单个库的压力。当然在大数据量的情况下,这些不同的库需要分放到不同的服务器中去,这样才能真正的提高单个库的处理能力。
2)垂直分表:
对于一个表中,字段太多的进行拆分为多个表来存储数据。可以把那些不常用的、数据比较大的(例如text、blob类型字段)拆分到扩展表去,避免数据量太大造成跨页问题,造成额外的性能开销。另外数据库是以行为单位将数据加载到内存中,这样表中的字段少,且访问频率高,内存能保存更多的数据,减少磁盘IO,从而提升了数据库的性能。
3)垂直拆分的优点:
- 解决业务系统层面的耦合,业务清洗。
- 与微服务方案类似,能对不同的业务的数据进行分层管理、维护、监控、扩展等。
- 高并发的情景下,垂直拆分能一定程度的提升IO、数据库连接数、单机硬件资源的瓶颈。
4)垂直拆分的缺点:
- 部分表无法使用join,只能通过接口聚合方式解决,提升了开发的复杂度。
- 分布式事务处理复杂。
- 依然存在单表数据量太大的问题(需要水平切分)。
2,水平拆分:
1)水平分表:
mysql单表达到1000W以上的数据之后,性能都会有所下降,这时候可将表按照某种规则切分到多张表中,但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。
2)水平分库:
将单张表的数据分发到多个服务器的数据库去,每个服务器都有相应的库和表,只是表中的数据集合不同。这样能缓解单机、单库的性能瓶颈,突破IO、连接数、硬件资源等瓶颈。
3)常见的分库分表策略:
- hash取模:假设按照user id分成10个表,那么规则就是对10取模。当id=1在表1中,当id=12就在表2中,以此类推。
- 范围分片:1-10000为一个表,10001到20000一个表,一以此类推。
- 地理位置分片:按照华南、华东、华北来区分表。
- 时间分片:按季度、月份、每日等进行划分,随着时间的推移,越长时间的数据被查询的概率就越低,可以做冷热数据。
4)水平拆分的优点:
- 不存在单库单表数据量过大,高并发性能瓶颈,提升系统的稳定性和负载能力。
- 应用端改造小,不需要拆分业务。
5)水平拆分的缺点:
- 跨分片的事务一致性难以保证。
- 跨库的join关联查询性能较差。
- 数据多次扩展难度和维护量极大。
6)范围分片和时间分片的优缺点:
优点:
- 天然便于水平扩展,后期如果要扩展机器,只需要添加新的节点即可,无需对其他的分片进行迁移。
- 使用分片字段进行范围查询时,连续分片可以快速定位分片进行快速查询,有效避免跨分片查询问题。
缺点:
- 热点数据成为性能瓶颈。连续分片可能存在数据热点,例如按时间字段分片,有些时间比较长的数据,很少被查询到,而近期的数据可能会被频繁读写。
7)hash取模的优缺点:
优点:
- 数据比较均匀,不容易出现热点数据和并发访问瓶颈。
缺点:
- 后期分片集群扩展比较麻烦,需要迁移旧数据。
- 容易面临跨片查询复杂问题,需要查询所有的数据库数据表。
三、分库分表面临的问题
1,分布式事务问题:
分库分表后,必然会涉及到跨库执行SQL的问题,这样就引入了分布式事务问题。
解决方案:
- 使用分布式事务中间件。
- 使用mysql自带的针对跨库的事务一致性方案(XA),不过性能要比单库慢10倍左右。
- 避免跨库操作。
2,跨库join问题:
分库分表后,表之间的关联操作受到了限制,不能join不同库之间的表,也无法join分表粒度不同的表,结果原本一次查询能完成的操作,可能需要多次查询才能完成。
解决方案:
- 全局表:基础数据,所有的数据库都拷贝一份。
- 字段冗余:这样有些字段就不用去join查询。
- 系统层组装:分别查询出所有数据,然后组装起来,比较复杂。
3,横向扩容问题:
使用hash取模做分表的时候,如果后期需要对数据表新加新分表,此时需要考虑重新hash之后的数据迁移的问题。
4,结果集合并、排序问题:
数据倍分散到不同的库,不同的表里,当我们需要对某字段进行合并、排序的时候,就会引发数据的合并、排序问题。
解决方案:
- 先在不同的分片节点中间数据排序并返回,然后将不同分片的返回结果进行汇总和再次排序,最终返回给用户。
四、mycat中间件的使用
mycat通过定义表的分片规则来实现分片,每个表格可以捆绑一个分片规则,每个分片规则指定一个分片字段并绑定一个函数,来实现动态分片算法。
- schema:逻辑库,与 mysql中的database(数据库)对应,一个逻辑库中定义了所包含的table。
- table:逻辑表,即物理数据库中存储的某一张表,与传统的数据库不同,这里的表需要声明其所存储的逻辑数据节点datanode。在此可以指定表的分片规则。
- datanode:mycat的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过datasource来关联到后端的某个具体的数据库上。
- datasource:定义某个物理数据库的访问地址,用于捆绑在datanode上。
- 分片规则:前面讲解了数据库的分库分表,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种规则把数据分配到某个分片的规则就是分片规则。
1,创建数据库、数据表:
创建两张表users和item,三个数据库db01, db02, db03。users表只存在db01中,item表被分割到db02, db03中。
create database if not exists db01;
use db01;
CREATE TABLE users (
id INT NOT NULL AUTO_INCREMENT,
name varchar(50) NOT NULL default '',
indate DATETIME NOT NULL default '0000-00-00 00:00:00',
PRIMARY KEY (id)
)AUTO_INCREMENT= 1 ENGINE=InnoDB DEFAULT CHARSET=utf8;
create database if not exists db02;
use db02;
CREATE TABLE item (
id INT NOT NULL AUTO_INCREMENT,
value INT NOT NULL default 0,
indate DATETIME NOT NULL default '0000-00-00 00:00:00',
PRIMARY KEY (id)
)AUTO_INCREMENT= 1 ENGINE=InnoDB DEFAULT CHARSET=utf8;
create database if not exists db03;
use db03;
CREATE TABLE item (
id INT NOT NULL AUTO_INCREMENT,
value INT NOT NULL default 0,
indate DATETIME NOT NULL default '0000-00-00 00:00:00',
PRIMARY KEY (id)
)AUTO_INCREMENT= 1 ENGINE=InnoDB DEFAULT CHARSET=utf8;
2,安装mycat
访问http://dl.mycat.io先下载安装包Mycat-server-1.6.7.1-release-20200209222254-linux.tar.gz。
然后解压压缩包并建立软连接:
tar -xvf Mycat-server-1.6.7.1-release-20200209222254-linux.tar.gz
mv mycat/ /usr/local/mycat
ln -s /usr/local/mycat/bin/mycat /usr/bin/mycat
启动mycat:
mycat start
查看日志是否成功:
cat /usr/local/mycat/logs/wrapper.log

停止mycat:
mycat stop
3,配置mycat配置文件
进入到mycat的配置文件目录:
cd /usr/local/mycat/conf/
编辑server.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<!--
<property name="processors">32</property>
<property name="processorExecutor">32</property>
<property name="bindIp">0.0.0.0</property>
<property name="frontWriteQueueSize">4096</property>
<property name="idleTimeout">300000</property>
<property name="mutiNodePatchSize">100</property>
-->
<property name="defaultSqlParser">druidparser</property>
<property name="mutiNodeLimitType">1</property>
<property name="serverPort">8066</property>
<property name="managerPort">9066</property>
</system>
<!-- 任意设置登陆 mycat 的用户名,密码,数据库 -->
<user name="test">
<property name="password">123456</property>
<property name="schemas">mycatdb</property>
</user>
<user name="user">
<property name="password">123456</property>
<property name="schemas">mycatdb</property>
<property name="readOnly">true</property>
</user>
<!--
<quarantine>
<whitehost>
<host host="127.0.0.1" user="mycat"/>
<host host="127.0.0.2" user="mycat"/>
</whitehost>
<blacklist check="false"></blacklist>
</quarantine>
-->
</mycat:server>
编辑rule.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="role1">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
</mycat:rule>
编辑schema.xml文件:
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 设置表的存储方式.schema name="mycatdb" 与 server.xml中的 TESTDB 设置一致 -->
<schema name="mycatdb" checkSQLschema="false" sqlMaxLimit="100">
<table name="users" primaryKey="id" dataNode="node_db01" />
<table name="item" primaryKey="id" dataNode="node_db02,node_db03" rule="role1" />
</schema>
<!-- 设置dataNode 对应的数据库,及 mycat 连接的地址dataHost -->
<dataNode name="node_db01" dataHost="dataHost01" database="db01" />
<dataNode name="node_db02" dataHost="dataHost01" database="db02" />
<dataNode name="node_db03" dataHost="dataHost01" database="db03" />
<!-- mycat 逻辑主机dataHost对应的物理主机.其中也设置对应的mysql登陆信息 -->
<dataHost name="dataHost01" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="server1" url="127.0.0.1:3306" user="root" password="123456"/>
</dataHost>
</mycat:schema>
4,启动mycat并连接上使用:
mycat start
mysql -utest -p123456 -h127.0.0.1 -P8066 -Dmycatdb
现在再通过命令查看数据库和表,发现只有逻辑数据库mycatdb和users, item表。
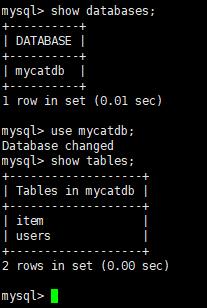
现在往表里插入数据:
insert into users(name,indate) values('aa',now());
insert into users(name,indate) values('bb',now());
insert into item(id,value,indate) values(1,10,now());
insert into item(id,value,indate) values(2, 20,now());
查看两个表可以看到所有的数据:
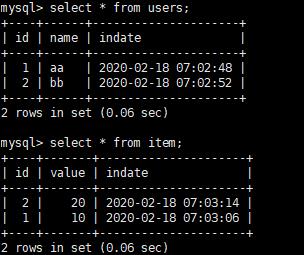
然后推出之后登录mysql,查看item表是否均匀的分布再db02和db03中:

注意:这里使用的是mysql5.7版本,mysql8.0版本会存在密码加密不同的问题,登陆不上mycat。需要先修改mysql8.0的加密方式和指定登陆mycat的密码加密方式,详细可看http://mini.eastday.com/mobile/190729090941846.html。
五、python使用mycat查询数据
import pymysql
def demo():
#创建connection连接
conn = pymysql.connect(
host = '192.168.0.215',
port = 8066,
user = 'test',
password = '123456',
database = 'mycatdb',
charset = 'utf8'
)
#获得cursor对象
cursor = conn.cursor()
#SQL语句
sql = "select * from item;"
#执行语句
cursor.execute(sql)
#获取查询数据
ret = cursor.fetchall()
#关闭对象,连接
cursor.close()
conn.close()
#打印结果
for i in ret:
print(i)
if __name__ == '__main__':
demo()
