
redis集群搭建
作者:向前的步伐 / 发表: 2020年2月5日 21:47 / 更新: 2020年2月5日 21:47 / redis / 阅读量:698
一、简介
redis是一个开源的key value存储系统,在redis3.0之前只支持单例模式,在redis3.0之后才开始支持集群模式。一般情况下,哨兵模式已经能满足一般的生产需求,具备了redis服务的高可用性。但是当数据达到一台服务器存放不下的情况,主从模式或者哨兵模式就不能满足需求。这个时候就需要对数据进行分片,将数据存储到多个redis实例中,集群模式就能解决单机redis容量的问题。
redis集群是主从模式和哨兵模式的结合体,拥有主从复制和master节点重选功能,如果要搭建2副本3分片的集群,就需要6个redis实例。
启动redis集群也比较容易,只要在redis的配置文件中,配置上cluster-enabled yes即可启动为redis集群模式,每个集群至少要有3个master节点才能正常运行,因为为了实现集群的高可用,redis集群有一个投片容错机制,如果集群中超过半数节点认为某节点挂了,那才能确定某个节点是真的挂了。3个中挂了1个,另外2个同时检测到某节点挂了,才能超过半数,所以至少需要3个master节点。
一般主节点挂了,从节点会自动升级为主节点。如果redis集群中,某个主节点挂了,而且该主节点没有从节点,那么这个集群也就会挂了。因为集群内置了16384个slot(哈希槽),并且把这些slot平均分配到各个节点。当redis集群要存放一个数据时,redis会先对这个key进行哈希算法,然后该值进行16384求余得到一个结果,再把数据分配到指定的哈希槽中。所以一旦某一个节点的不能用了,该slot也就不能用了,那么redis集群就不能正常工作。
redis集群特点:
- 多个redis节点网络互连,数据共享。
- 所有节点都是一主一从(也可以是一主多从),其中从节点不提供服务,只是作为备份。
- 不支持同时处理多个key(如MSET/MGET或pipeline),因为redis把key均匀分配到各个节点上,不同的key会分配到不同的哈希槽中。
- 支持在线增加、删除节点。
- 客户端可以连接任何一个主节点进行读写。
二、安装高版本redis
1,首先安装redis编译依赖的环境:
yum -y install make gcc*
2,下载redis:
wget http://download.redis.io/releases/redis-5.0.7.tar.gz
3,进入到redis目录
cd redis-5.0.7
4,编译安装redis:
make MALLOC=libc && make install
三、redis集群模式搭建
1,准备3台虚拟机,分别启动两个redis服务器:
192.168.1.202 端口:7001,7002
192.168.1.203 端口:7001,7002
192.168.1.204 端口:7001,7002
2,创建项目目录并复制redis.conf文件:
mkdir cluster_redis
cd cluster_redis
cp ../redis-5.0.7/redis.conf ./
cp redis.conf redis_7001.conf
cp redis.conf redis_7002.conf
3,修改redis配置文件:
在192.168.1.202服务器,先配置redis_7001.conf文件:
bind 0.0.0.0
port 7001
daemonize yes
pidfile "./redis_7001.pid"
logfile "./redis_7001.log"
dir "./data/redis_7001"
masterauth 123456
requirepass 123456
appendonly yes
cluster-enabled yes
cluster-config-file nodes_7001.conf
cluster-node-timeout 15000
再配置redis_7002.conf文件:
bind 0.0.0.0
port 7002
daemonize yes
pidfile "./redis_7002.pid"
logfile "./redis_7002.log"
dir "./data/redis_7002"
masterauth 123456
requirepass 123456
appendonly yes
cluster-enabled yes
cluster-config-file nodes_7002.conf
cluster-node-timeout 15000
其他两台服务器也是一样的配置,这里省略。
4,参数说明:
- cluster-enabled yes:如果配置为yes则开启redis集群功能,此redis实例作为集群的一个节点,否则它就是一个普通的redis实例。
- cluster-config-file nodes_7001.conf:这个文件不能人工编辑,它是集群自动维护的文件,主要用于记录集群中有哪些节点,它们的状态以及一些持久化参数等,方便在重启时恢复这些状态。
- cluster-node-timeout 15000:这个是集群节点的超时时间,如果超过这个时间还是不可达,那就认为是故障,用它的从节点启动故障转移,升级为主节点。
5,创建数据保存目录:
mkdir -p ./data/redis_7001
mkdir -p ./data/redis_7002
其他两台服务器也创建相同的目录,这里省略。
6,启动redis服务:
redis-server redis_7001.conf
redis-server redis_7002.conf
7,创建集群:
如果redis版本比较低,则需要安装ruby,任意一台机器安装ruby即可。redis5.0版本则不需要安装ruby,直接创建集群。
redis-cli -a 123456 --cluster create 192.168.1.202:7001 192.168.1.202:7002 192.168.1.203:7001 192.168.1.203:7002 192.168.1.204:7001 192.168.1.204:7002 --cluster-replicas 1
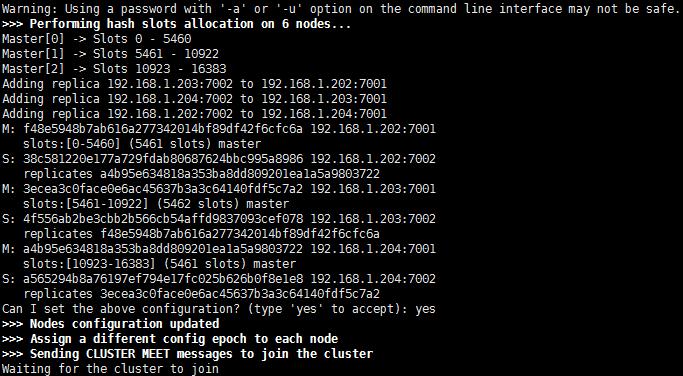
可以看到集群的信息:
192.168.1.202:7001是master,它的slave是192.168.1.202:7002;
192.168.1.203:7001是master,它的slave是192.168.1.203:7002;
192.168.1.204:7001是master,它的slave是192.168.1.204:7002;
自动生成nodes.conf,这里可以看到集群各个节点的信息:
vi data/redis_7001/nodes-7001.conf

8,登录集群:
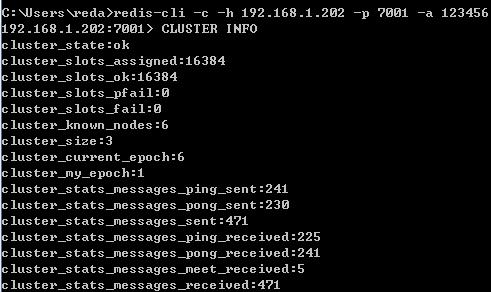
redis-cli -c -h 192.168.1.202 -p 7001 -a 123456 # -c,使用集群方式登录
查看集群信息,使用CLUSTER INFO命令,得到下面的信息:
查看节点信息,使用CLUSTER NODES命令,得到下面的信息:
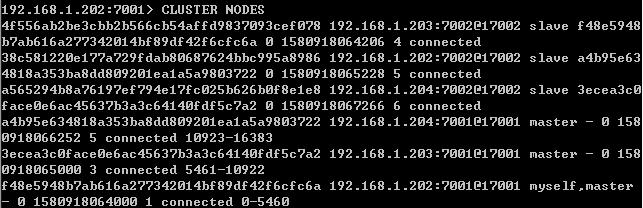
这里列出的内容和nodes.conf文件的内容相同。
现在,尝试写入数据,可以从返回的信息看到key存放在哪个节点:
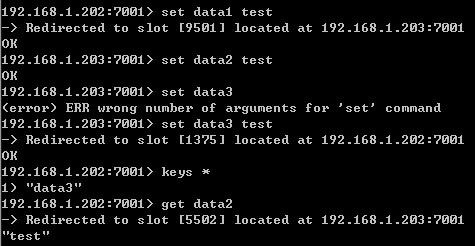
data1和data2在192.168.1.203:7001,data3在本机192.168.1.202:7001,“keys *"命令也只能看到本机的data3数据。同时在192.168.1.202:7001获取data2也是可以获取到值的,集群会自动跳转到192.168.1.203:7001获取到相应的key。
可以看出,redis集群是去中心化的,每个节点都是平等的,连接哪个节点都可以获取到数据。当然平等指的是master节点,不包括slave节点,slave节点不提供服务,只作为master的一个备份。
9,新增redis集群节点:
在192.168.1.202机器上新增配置文件redis_7003.conf:
bind 0.0.0.0
port 7003
daemonize yes
pidfile "/var/run/redis_7003.pid"
logfile "/usr/local/redis/cluster/redis_7003.log"
dir "/data/redis/cluster/redis_7003"
masterauth "123456"
requirepass "123456"
appendonly yes
cluster-enabled yes
cluster-config-file nodes_7003.conf
cluster-node-timeout 15000
并创建数据保存目录:
mkdir -p data/redis_7003
启动redis服务:
redis-server redis_7003
登录集群之后,使用CLUSTER MEET 192.168.1.202 7003命令增加新节点:
CLUSTER MEET 192.168.1.202 7003
同样可以再创建一个redis_7004,启动服务后添加入redis集群,这里就不重复展示。
最后我们看下现在集群中的redis节点信息:

从节点信息里可以看到,这里新加的节点都是以master的身份加入到redis集群的,如果我们想要新增从节点,可以使用“cluster replicate
redis-cli -c -h 192.168.1.202 -p 7004 -a 123456 cluster replicate 619623815413fef13f13f3184f50842157455c73
也可以登录redis集群之后,使用“CLUSTER REPLICATE
CLUSTER REPLICATE 619623815413fef13f13f3184f50842157455c73
这时候在看看节点信息:
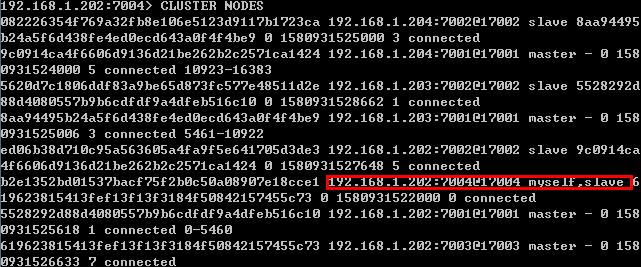
10,删除redis集群节点:
登录redis集群之后,使用“CLUSTER FORGET
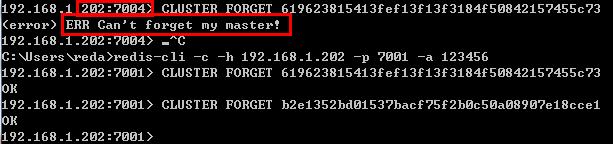
也可以使用命令直接删除需要删除的节点:
redis-cli -a 123456 --cluster del-node 192.168.1.202:7004 b2e1352bd01537bacf75f2b0c50a08907e18cce1
redis-cli -a 123456 --cluster del-node 192.168.1.202:7003 619623815413fef13f13f3184f50842157455c73
四、redis集群命令
- cluster info:打印集群信息。
- cluster nodes:列出当前集群已知所有节点,以及这些节点的相关信息。
- cluster meet
:将IP和PORT所指定的节点添加到集群中,让它成为一份子。 - cluster forget
:将当前节点设置为node id指定的节点的从节点。 - cluster saveconfig:将节点的配置文件保存到硬盘。
- cluster slaves
:列出node id所有从节点。 - cluster set-config-epoch:强制设置configEpoch。
- cluster addslots
[slot...]:将一个或者多个槽指派给当前节点。 - cluster delslots
[slot...]:移除一个或者多个槽对当前节点的指派。 - cluster flushslots:移除当前节点的所有槽,让当前节点变为空槽节点。
- cluster setslots
node :将槽指派给指定node id节点,如果该槽已经属性某个node id节点,那需要先删除再进行指派。 - cluster setslots
migrating :将本节点的槽迁移到node id节点上。 - cluster setslots
importing :从node id节点中导入槽到本节点。 - cluster setslots
stable:取消对槽的导入(import)或者迁移(migrate)。 - cluster keyslot
:计算key应该放在哪个槽上。 - cluster countkeysinslot
:返回槽目前包含的key的数量。 - cluster getkeysinslot
:返回count个槽中key。 - cluster myid:放回节点ID。
- cluster slots:返回节点负责的槽。
- cluster reset:重置集群,慎用。
五、python操作redis集群
1,先安装python操作集群的库:
这里需要使用到redis-py-cluster,但是不要使用pip install redis-py-cluster安装最新的包,它会附带安装redis-3.0.1包,但是这两个包不兼容,会出现在找不到StrictRedisCluster的问题,这里推荐安装redis-py-cluster的1.3.6版本,它会自动安装reids-2.10.6,这两个版本是兼容的。可以使用命令:
pip install redis-py-cluster==1.3.6
这里也可以看别人在安装redis-py-cluster遇到的坑,可参考。
然后创建一个python文件,写入以下代码测试:
from rediscluster import StrictRedisCluster
if __name__ == '__main__':
try:
# redis集群中的所有主结点(所有master结点)
startup_nodes = [
{'host': '192.168.1.202', 'port': '7001'},
{'host': '192.168.1.203', 'port': '7001'},
{'host': '192.168.1.204', 'port': '7001'},
]
# 构建StrictRedisCluster对象
src = StrictRedisCluster(startup_nodes=startup_nodes, password='123456', decode_responses=True)
result = src.set('data5','test5')
print(result) # True
name = src.get('data5')
print(name)
except Exception as e:
print(e)
